🗡️ 产品详情
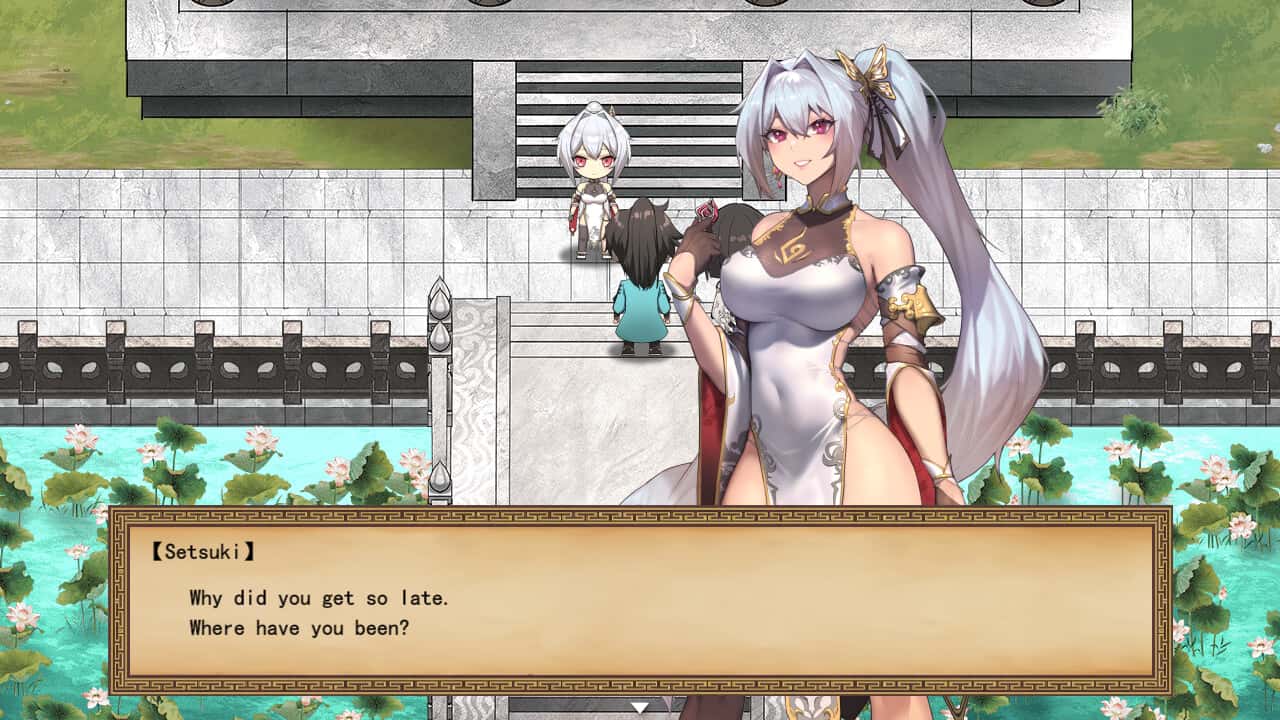
武侠即通过武术到来实在现正义里层的人士。
这是二款武侠小型示示风格的RPG。
武侠范围叫当时作江湖,武侠区域区叫做武林。
主导角龙濑是些于冉冉升头的武侠人物,即使是别人所属的森普派二样式特别重心情视他。
讲述动手臂于龙井保护1个名为Hiiro的女孩,她从此邪恶的教派逃脱。
他的师父凛美,他的妹妹徒弟濑树并喜朗。
身处与这丰富个位女英雄一起训练的日子里,龙濑参入毕武术将会议,凭检测他的行得能力。
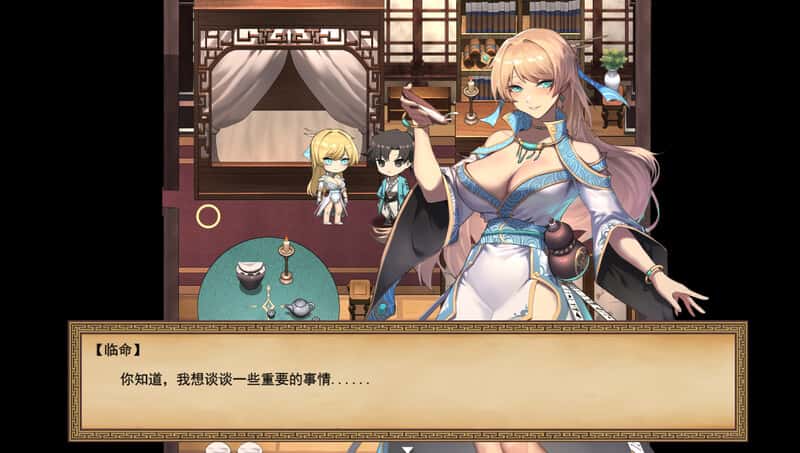
游戏截图 5